专注于靶向DIA蛋白
主要特性
架构优势
云平台架构、部署简单、硬件需求低、MongoDB 数据库支持
专业性
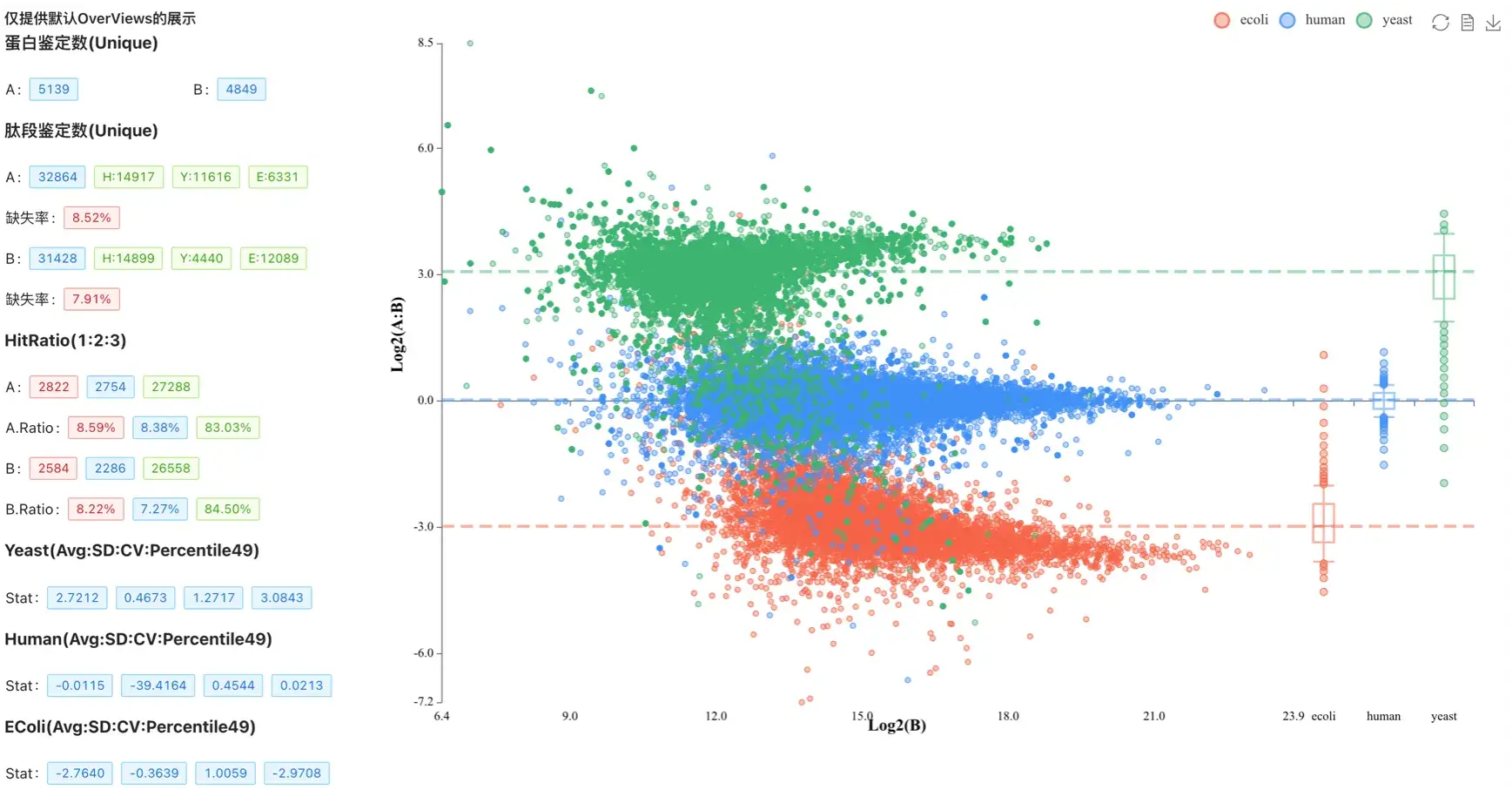
分析速度 6 倍提升、蛋白鉴定数目提高 10%、准确度提高 10%
易用性
不需要安装软件,浏览器访问、易于操作的可视化界面、全流程可视化图表、库文件与实验文件的管理
蛋白诊所
Peptide "Clinic"
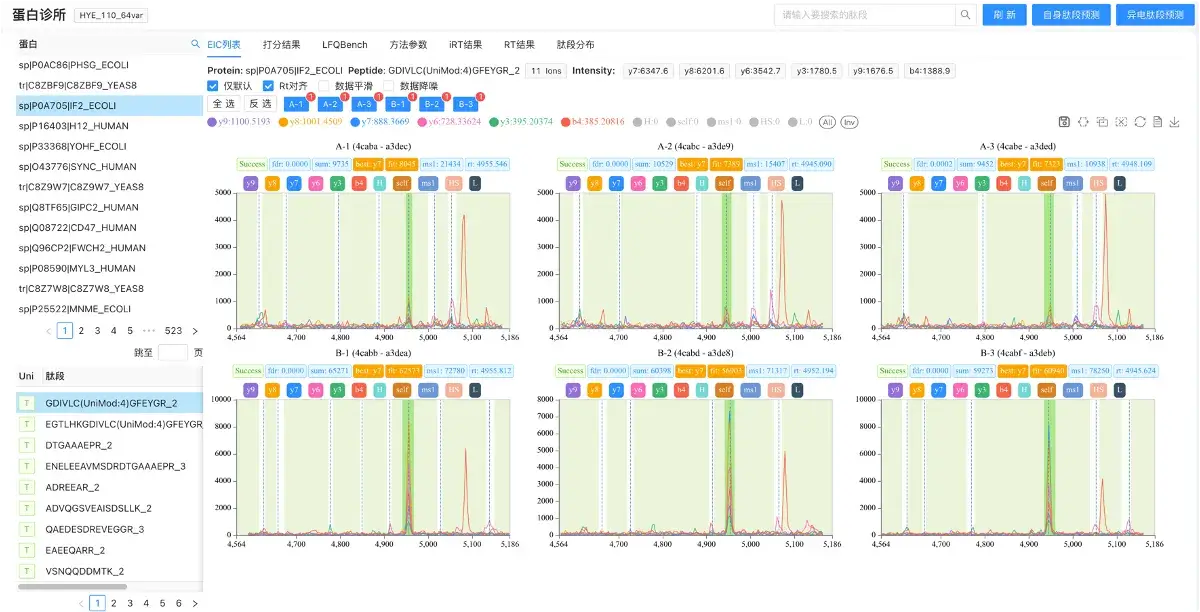
由于ProPro提供了对于每一个步骤的可视化操作,因此使用ProPro的信息学分析学者在跑完结果后往往会对某些肽段感到好奇,想要看看这些肽段的其他碎片的分布情况。肽段"诊所"就是这样实用的工具,基于Aird高速的IO能力,肽段"诊所"工具可以实时的枚举出一个肽段的C端或者N端的所有碎片的可能性,然后对这些可能出现的碎片实时生成标准库并进行卷积,我们称这个步骤为离子枚举填,当肽段进行了离子枚举填充后再进行分析,往往可以得到更多有用的信息。
EIC列表
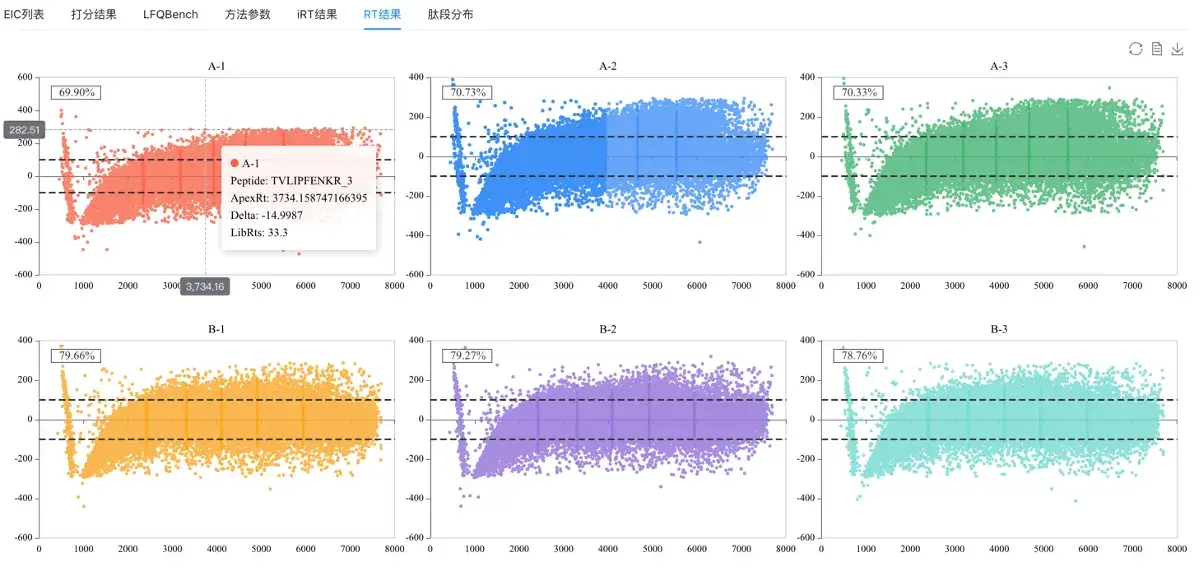
RT结果
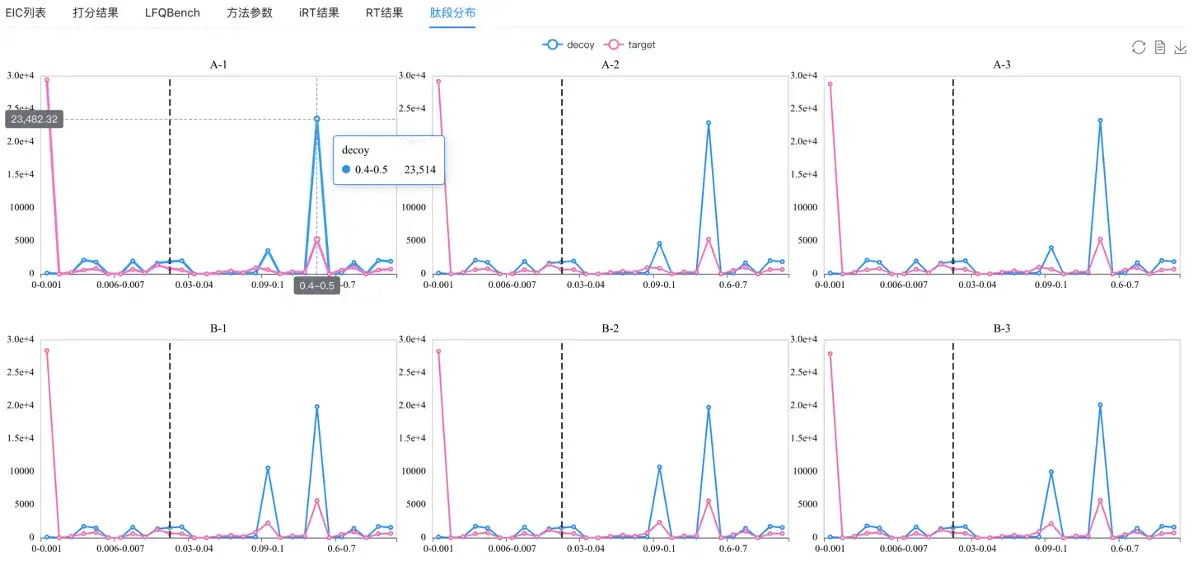
肽段分布
iRT结果
LFQBench

打分结果
核心模型
Project-Experiment Model
主要用于将同一批实验进行聚合管理,每一个项目中可以包含多个实验,方便进行批量操作。通常同一批实验会使用相同的标准库和系统调参,因此适合进行整个项目的批量操作处理,同时也大大加强了系统对于实验数目过于庞大时的项目管理能力
Experiment-Aird-Index Model
ProPro系统的核心模型,ProProClient将Vendor Raw File转化的过程将源文件拆成了三块:1.原始信息,包括操作人、质谱仪机型、数值精度、压缩策略、SWATH窗口信息等;2.索引信息,包含了对于每一个Spectrum的索引以及每一个SWATH Block的索引;3.高压缩的Aird数值文件,在这个模型中ProPro允许用户对索引和实验信息进行搜索操作,对原始谱图可以在搜索的基础上进行可视化展现。本模型的所有关联关系在经由ProProClient转换后形成并且存储与Aird.JSON的文件中。因此在ProProServer中可以通过导入JSON格式的索引文件迅速导入整个实验的基础信息及关联关系,每一个实验对应一个Aird文件,对应N个索引文件。索引文件包括两类:一类是每一个Spectrum的索引,一类是每一个SWATH Block的索引
Library-MS/MS Model
主要用于描述标准库或者是iRT库内的所有数据,是基于库搜索的DIA/SWATH-MS算法中最为重要的数据源之一。由于ProPro的Library-MS/MS模型是基于数据库存储的,因此天然的具备可搜索能力,使得TraML或者是CSV格式的标准库文件的可视化和可搜索化变得极为简单,每一个标准库对应多个MS1的信息,每一个MS1包含多个MS2的信息
Analysis-MS-Result Model
是ProPro中的输出结果模型,对于一个Experiment,一个给定的Library和一组合适的运行参数(包括卷积的mz窗口,卷积的RT时间窗口),通常我们会产生一个唯一的分析结果,这些结果以MS1为单位,和对应的标准库的MS1一一对应,分别展示每一个MS1的的Chromatogram的情况,选峰情况以及最终的打分值。一套算法是否合理,最终根据FDR选出的结果是否精准,ProPro均提供了可视化的界面让整个流程可以回溯